NEOFLEX
DATAGRAM
Low-code data engineering platform
СМОТРЕТЬ ВИДЕО
Хотите быстро разрабатывать аналитические решения на основе Big Data?
Используйте удобное и интуитивно понятное визуальное средство разработки
Сталкивайтесь с дефицитом специалистов в области Big Data?
Используйте опыт ваших ETL и SQL-разработчиков для визуальной разработки процессов обработки данных
Хотите упростить поддержку сложных решений, построенных на технологиях Big Data?
Вносите изменения быстро и легко за счет визуального представления потоков данных и процессов их обработки



Визуальное проектирование Data Pipelines и автоматическая генерация кода на языке Scala
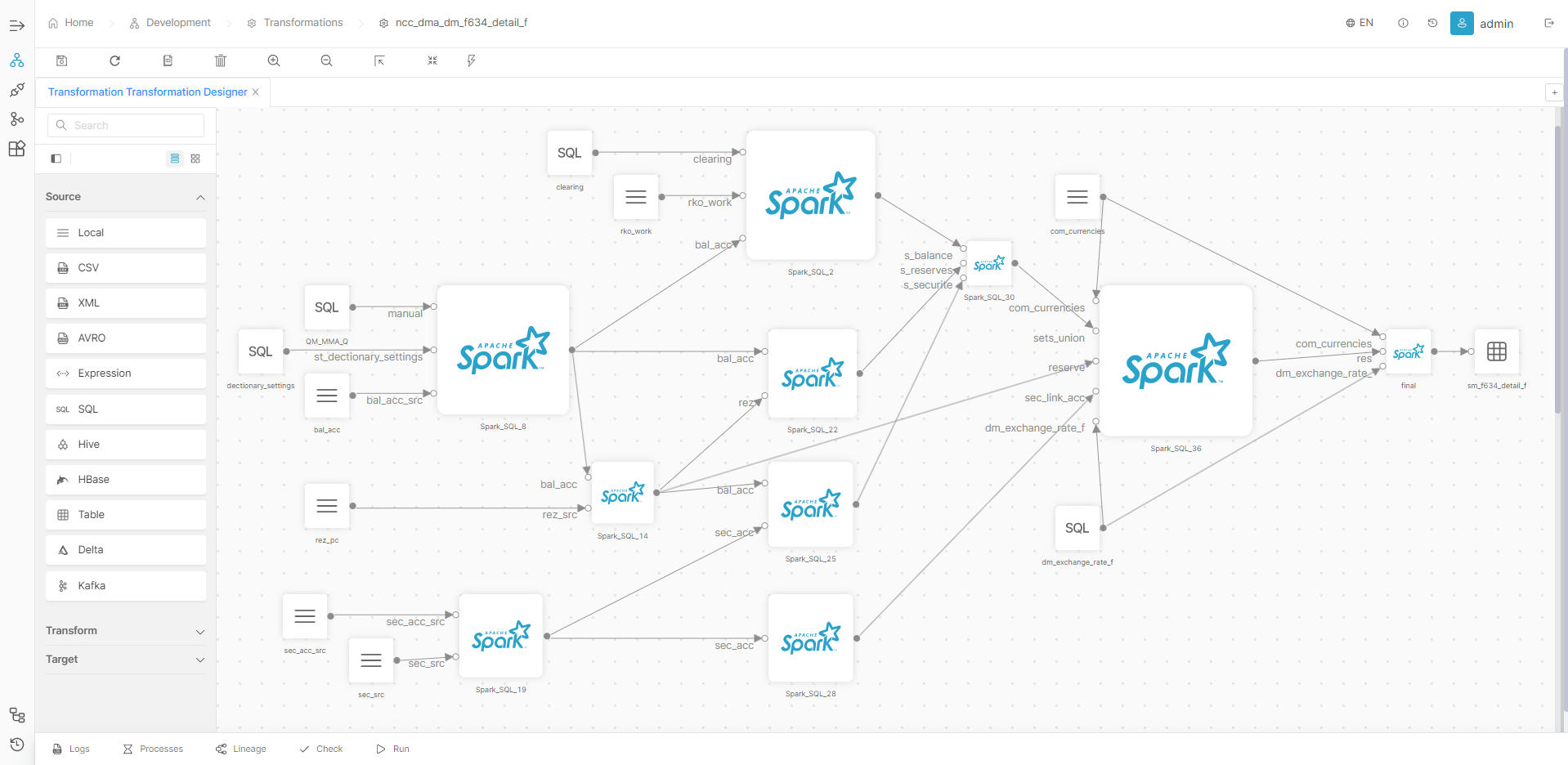
Используйте всю мощь библиотек Apache Spark для пакетной и потоковой обработки данных без необходимости написания кода на Scala в ручную. Scala-код будет сгенерирован автоматически с использованием подхода Model Driven Architecture по специальным моделям.
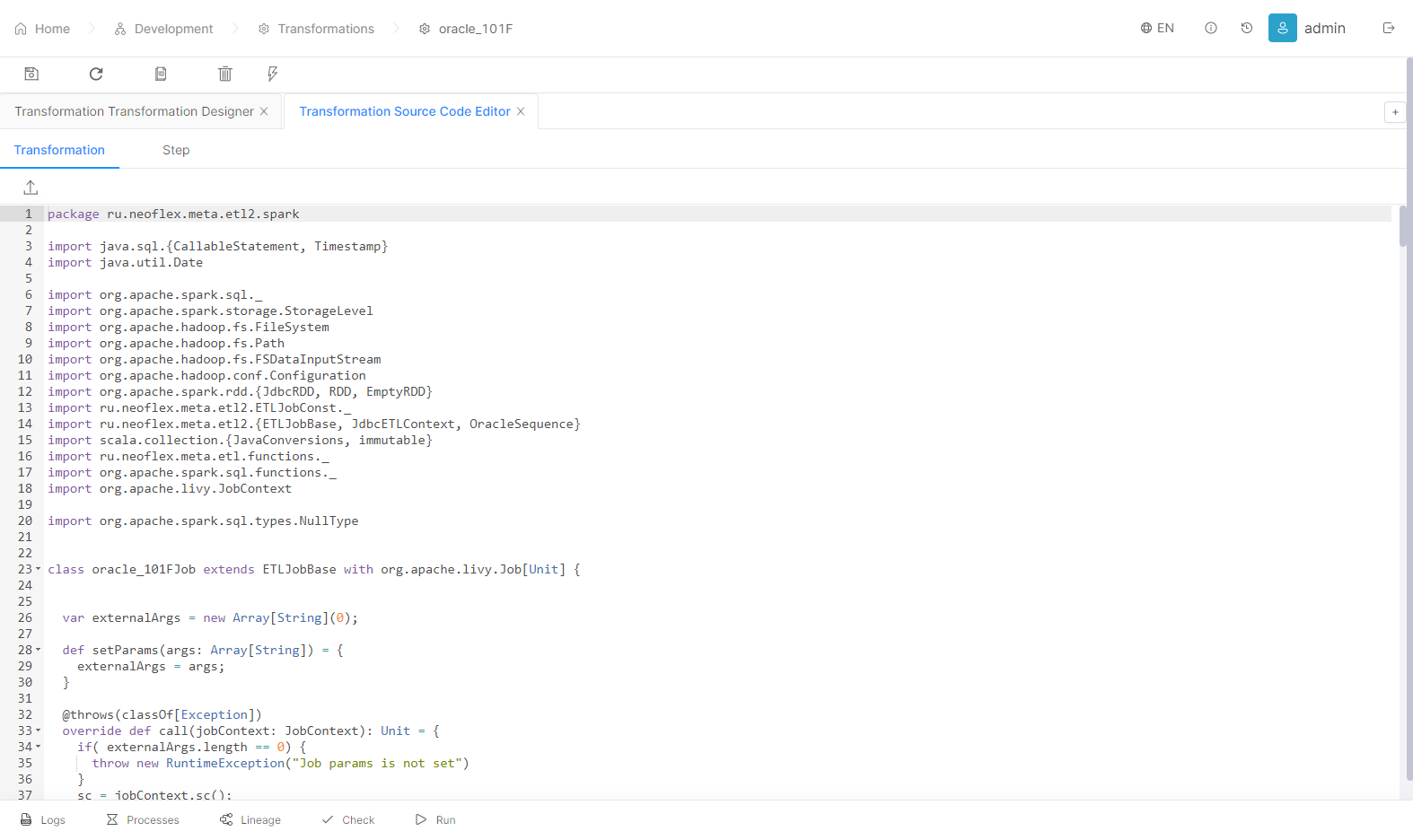

Datagram предоставляет удобные средства для отладки и оптимизации:
Просмотр содержимого, структуры источников и приемников;
Отслеживание происхождения объектов потока данных до отдельных полей (lineage);
Частичное выполнение преобразования с просмотром промежуточных результатов;
Выполнение отдельных шагов и веток преобразований;
Просмотр сгенерированного кода приложения;
Автоматическая валидация трансформации;
Поддержка Spark Catalyst Optimizer.
Загрузка данных любых источников в 2 клика
Загружайте данные на основе метаданных источников as-is, не опускаясь на уровень разработки source-to-target мэппингов. Экспортируйте метаданные источников в Apache Atlas для выстраивания инфраструктуры Data Governance и управления данными на уровне всей организации.

Streaming Processing
Проектируйте процессы потоковой обработки данных и получайте результаты вычислений в промежуток времени до нескольких милисекунд после появления данных.
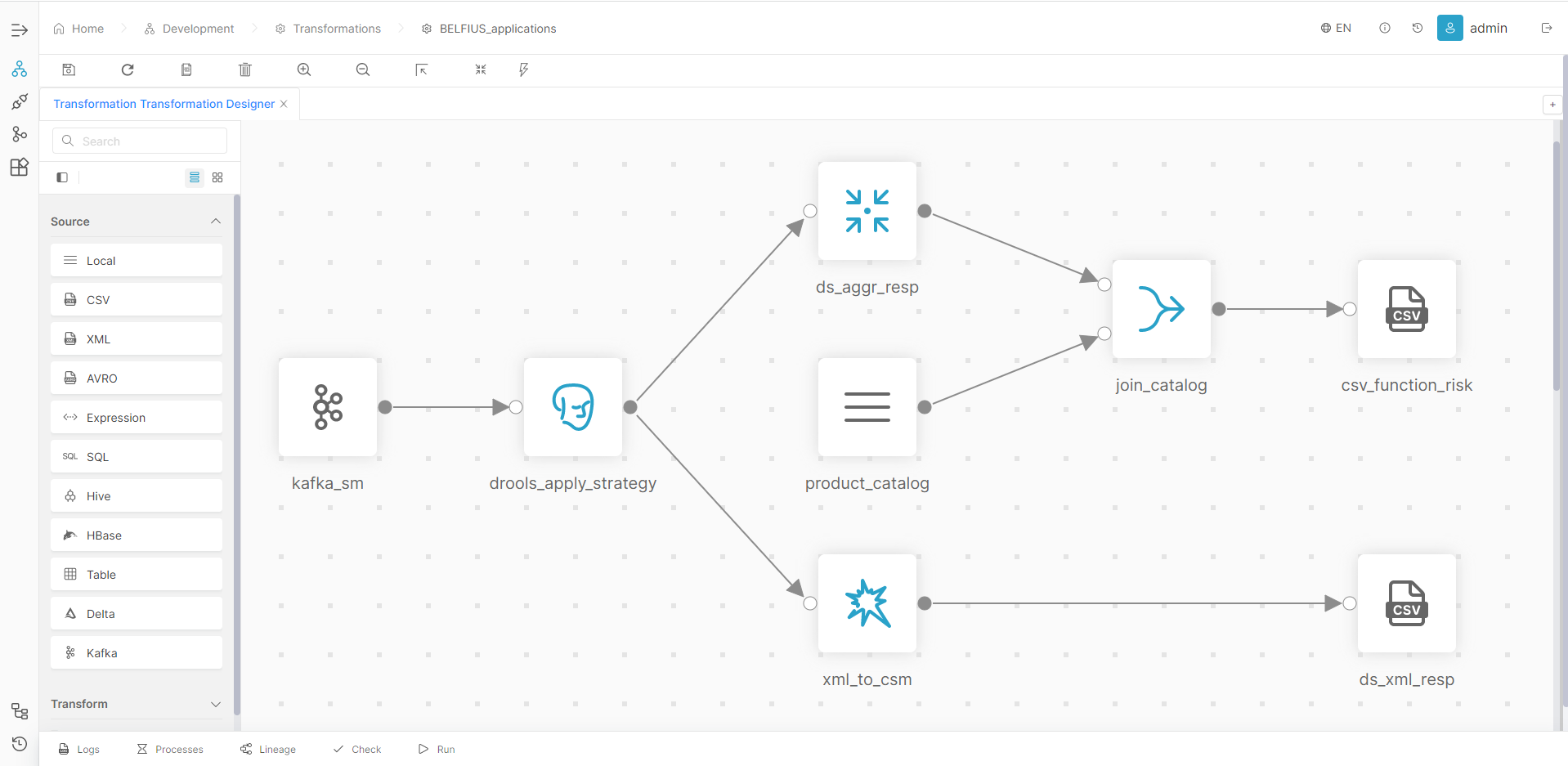
Используйте Kafka и Spark Streaming для обработки данных в потоковом режиме. Создавайте и применяйте бизнес-правила для потоков событий в реальном времени за счет нативной интеграции с BRMS.


Data Pipeline с логикой
любой сложности
Встраивайте алгоритмы Artificial Intelligence/Machine Learning и бизнес-правила в потоки обработки данных.
Out-of-box доступен самый широкий спектр инструментов по обработке данных:
Анализ на основе машинного обучения с использованием Spark MLlib (decision trees, SVM, logistic regression и т.д.);
Jboss Rules (Drools);
Широкий набор операций реляционной алгебры: join, sort, aggregation, union, selection, projections, pivot, explode arrays, sequence generation;
Spark SQL.

Поддержка DevOps и CI/CD Pipeline
Захват изменений
из репозитория
Интеграция с системами
контроля версий
Сборка
и установка модулей
Поддержка UNIT-тестов
Запуск созданных
приложений
Запуск приложения не зависит от среды разработки


Уже используют в своей работе

DATAGRAM включен в Единый реестр российского ПО. Подробнее
